I had a list of a couple thousand files. I got the list as an export from a program, but I could also have gotten it from a directory listing at a command prompt (e.g., DIR /a-d /b /s). This post describes how I used that list to rename those files. Needless to say, since I was working with the possibility of screwing up years' worth of information, I did make a backup of these files before proceeding.
This particular list was a list of emails that I had just exported from Thunderbird, as described in another message that I expect to post to this blog on the same day as this one. I had exported, not only the list, but also the actual emails, in EML format. I planned to use the list to rename those EMLs so that they would be in the format I wanted, which was like this:
2011-03-20 14.23 Email to John Doe re Tomorrow.pdf
It would require some massaging to get there.
The Date and Time Segment
Starting with the date and time, here's what Thunderbird had given me in the list of files:
3/20/11 14.23
These were all in one field, in the .csv (i.e., Excel-readable) output from T-bird. They might have been in two or more fields, in a text file produced by a directory listing (e.g., DIR /a-d /b /s > dirlist.txt), but to some extent the same techniques might prove useful. These numbers were not in a format that would work as a Windows filename, and in fact the exported EMLs did not contain the date and time data in this format.
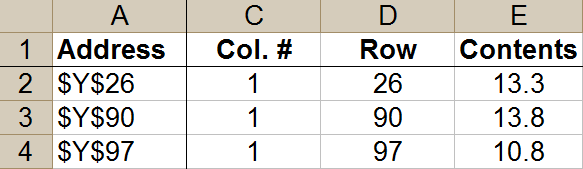
I was going to use the list to rename the emails the way I wanted, with data that existed in the list but not in the current EML filenames. To do that, I would need to try to get the list so that it accurately represented the actual EML filenames. Otherwise, if the list produced a command that said, Rename File 234A.eml to be "Message from Ray 234A," that command would not work if the file being renamed was actually called File_234A.eml (with an underscore). My command would just get a "File not found" error. So my first step was to find a way, in my Excel spreadsheet, to reproduce what the files were actually called, as I viewed them Windows Explorer.
First, I would have to extract each element into a separate column, there in the spreadsheet, so that I could format and rearrange them as desired. For this, I started with FIND commands. (Excel's internal help had good information on using these and other related commands. I was doing this in Excel 2003. There might have been other functions that would automate this process in newer versions.) For instance, =FIND("/",A1) would locate the first occurrence of the forward slash in cell A1, if that's where I put the "3/20/11 14.23" item shown above. So then I could search for the next slash (=FIND("/",A1,B1+1), starting one place after the results of the first FIND statement (which, in this example, I had put in cell B1). I could do the same for spaces, colons, or whatever else might delimit various components of the date and time entry. I'd then use RIGHT, LEFT, or MID statements to find those components. For instance, a MID statement like =MID(A1,B1+1,C1-B1-1) might start one space after the first slash, continue to one space before the second slash, and thus give me the day of the month.
In the 3/20/11 14.23 example, the value of "3" for the month wouldn't give me the desired "03" so I would use IF and LEN statements to pad that out:
=IF(LEN(G1)=1,"0","")&G1
thereby inserting a zero in front of single-digit month values found in cell G1, but adding nothing to those month values if they were not single-digit.
I had gotten two different things from Thunderbird. On one hand, as noted above, I had gotten a list of data about emails that I was going to export, with dates in the 3/20/11 format. On the other hand, I had also gotten the actual emails, exported as individual EML files. These were not named quite the same way. The particular Thunderbird extension that I had used to produce this list of files, ImportExportTools, had produced files whose names were in this format: Date-Time-Sender-Subject. But in those filenames, the dates could not be rendered as 3/20/11, since slashes were not allowed in Windows 7 filenames. Instead, the date and time came in the format of 20110320-1423. So as hinted above, I would ultimately be producing a batch file that would automate the renaming of thousands of files. That example, 20110320-1423, would instead begin with the more readable 2011-03-20 14.23.
Next: Massaging the Sender Data
Before I could get to that point, I had to change some of the Sender data that T-bird had produced. Again, the list of actual email data from T-bird contained characters (e.g., the > symbol) that could appear in email Subject lines but that were not allowed in Windows 7 filenames. (The full set of forbidden characters: \ / : * ? " < > | ). For example, the spreadsheet might show a sender to be this:
John Doe <jdoe@xcom.com>
but the actual exported EML file's name would just have John Doe. So I could get rid of some of these problems of
verboten characters by just doing a FIND for < and then a MID or a LEFT statement for everything before that. That wouldn't necessarily get rid of all the bad-character problems, but I wanted to clean those up just once, so I deferred that problem for the moment. For right now, in a bid to match the format of the exported EMLs, I now had this much of the filename:
20110320-1423-John Doe
To get there, the actual command I used, for the Sender portion, was this:
=LEFT(B2,V2-1)
Cell B2 had the Sender's name as exported from Thunderbird, and cell V2 had the FIND location for the < symbol, which marked the end of the part of the Sender data that I planned to use.
At this point, there was a problem. For some reason, ImportExportTools put underscores before and after some Senders' names, but not all. So I might instead have this:
20110320-1423-_John Doe_
The filenames already used a hyphen ( - ) to delimit fields, so the combination hyphen-underscore seemed superfluous. It needed to be fixed before I could continue with the main project here, so that I could be confident that Sender names were delimited consistently by a hyphen, and not by unpredictable choices involving underscores.
Detour: Renaming Thousands of Files, So That I Could Proceed to Rename Thousands of Files
To fix this problem, I went to the Windows 7 command prompt (Start > Run > cmd) and did a directory listing to save the filenames to a file: DIR /b > dirlist.txt. I copied the contents of that file into column A of a new Excel spreadsheet. I also copied those contents into Notepad. In Notepad, I did two global replaces (changing both -_ and _- to just plain - ). I copied those changed contents into column B of that Excel spreadsheet. Next, I needed to combine these two columns, A and B, into a single DOS command that would rename the files. To do that, I put this formula in column C:
="ren "&char(34)&A1&char(34)&" "&char(34)&B1&char(34)
The char(34) entries would introduce quotation marks: 34 was the ASCII code for double quotes. I could have introduced any character that way -- Z, a semicolon, whatever -- but it was essential to use the char(34) approach for quotation marks specifically because otherwise Excel would have misunderstood them. Quotation marks would be necessary for any DOS command involving filenames that contained spaces; DOS would otherwise think that the space marked the end of a part of the command. Anyway, I copied the contents of column C back into Notepad and saved the file as a batch file (renamer.bat). I saved renamer.bat in the folder where I had all those EML files I was going to rename. At a DOS prompt in that folder, I typed "renamer.bat," without the quotes. I could have just double-clicked on renamer.bat in Windows Explorer. Either way, the files were renamed.
Later, I discovered that ImportExportTools would truncate the Subject field in the spreadsheet to 50 characters even if I had not asked it to do so. Many emails in my set had Subject fields longer than that. I initially tried to fix this by setting up a separate spreadsheet, using the process just outlined, but with
a search for the last hyphen in the filename, which would hopefully identify the start of the Subject field in most cases. Unfortunately, the calculation of 50 characters proved difficult, after taking into account the character substitutions described here. Ultimately, I started over with a fresh export of EML files from Thunderbird, after setting the option at Tools > ImportExportTools > Options > Filenames tab > Cut subject at 50 characters (and also Cut complete file path length at 256 characters).
Returning to the Sender and Subject Segments
So now I could go back to work on the main spreadsheet. I could assume, that is, that the first part of the EML filenames were going to look like this:
20110320-1423-John Doe
without underscores. I could see that there were still a few underscores around names in the EMLs, and that was problematic. Possibly ImportExportTools had introduced two underscores rather than one in a row, in some cases. There were few enough that I figured I could fix those exceptions manually.
Now it was time to add the Subject part of the filename. This was simple enough: just use another ampersand (&) to combine it with the rest. Sketching it out, the EMLs now just used hyphens to delimit the date, time, sender, and subject portions, so I just needed to use an Excel command of this format:
=[Date]&"-"&[Time]&"-"&[Sender]&"-"&[Subject]&".eml"
and that would give me a complete representation of how ImportExportTools seemed to have constructed the filenames for most of the exported EMLs.
Cleaning Up Unwanted Characters
As noted above, some characters (e.g., the colon, ":") were not acceptable as Windows 7 filenames, but were quite common in email subject lines. It looked like ImportExportTools had replaced those characters with an underscore, and had removed spaces before and after the underscore. So, for instance, a subject line of "Re: Tomorrow" was represented, in the EML filenames, as "Re_Tomorrow," without a space.
At this point, preparing to remove those unwanted characters, my spreadsheet had something like this:
20110320-1423-John Doe-Re: Tomorrow
Some of these fledgling combinations contained other unwanted characters (e.g., question marks), listed above. I was almost ready to remove them. But first, it was time to proofread my spreadsheet. Having copied all of my various formulas down from the first line of the spreadsheet, where I was developing them, so that they were present in all rows, I now prepared to sort the spreadsheet. First, I inserted an Index column as column A, and in that column I inserted numbers in ascending order, starting with 1. The purpose of this column was to remember my original sort order, in case the date field or anything else did not accurately reproduce the order in which emails appeared in Thunderbird. There were times when a person would want to check back and see if things were matching the source. To insert these numbers, using Excel 2003, there were two options. One was to enter a formula in each cell, adding 1 to the number above it, and then replace the formulas with fixed values. The sequence for this was Edit > Copy, Edit > Paste Special > Values. An alternative was Edit > Fill > Series. Either way, I now had index numbers that wouldn't change if I sorted rows.
So now I did sort rows, sorting first on the column that concatenated (i.e., combined) the date, sender, and subject. I sorted to highlight those rows in which the process had not worked as intended. One problem, I saw, was that some Sender names did not include the <jdoe@xcom.com> part. The sender of these emails was just listed as John Doe (or whoever), without the actual email address. For these, I just copied the Sender straight over, skipping the unnecessary part of the spreadsheet calculation. That cleared up the error messages in the spreadsheet. So now I saved a version of the spreadsheet and moved the output column -- the one combining all of my work with these various fields -- and pasted it into Notepad. I could have edited it right there in Excel, but there was a risk that I would accidentally have changed other columns in ways that I did not intend, or that I could not achieve what I needed to achieve. For example, the ? symbol was a wildcard in Excel, so attempting to replace it with an underscore would either not work or create a mess. I noticed that ImportExportTools had also converted commas into underscores, even though they were not forbidden characters. Note: now that I had parts of the spreadsheet in Notepad, and expected to paste those parts back into Excel in the same order, this would have been an especially bad time to sort the spreadsheet.
Over in Notepad, I did global find-and-replace operations for each of the special characters listed above, guided by the objective of matching as closely as possible the actual filenames of the EMLs I had exported from Thunderbird. It was premature to do line-by-line editing of individual entries, though; those would be more obvious and perhaps more easily fixed later. At this point, if I saw something that needed to be changed, I executed it as a global command, so that it would be changed wherever it occurred. Obviously, a person can make serious mistakes with global changes so, again, this was not the time for fine-detail fixes of individual entries. On the other hand, each of these global changes was a potential time-saver: a single change here could save the need to make manual changes to 20 or 300 individual files later.
After making these changes, I again had to replace the -_ and _- combinations with a simple hyphen ( - ), since some forbidden characters that I had just replaced with underscores had been adjacent to the delimiting hyphens that ImportExportTools seemed to convert into simple hyphens. With these changes made, I copied the contents of that Notepad file back into the appropriate place in the spreadsheet.
Testing the Filename Match
How well did my spreadsheet now reflect the actual names of those EML files? I decided to test it. To do this, I first made a backup copy of the folder containing the EMLs. I then created a subfolder in the EMLs folder, called Test. In the spreadsheet, I worked up a MOVE command for each file, commanding it to move to the Test folder. The command was like this:
="move "&CHAR(34)&Z2&".eml"&CHAR(34)&" Test"
I copied all those MOVE commands from the spreadsheet to Notepad and saved the Notepad file as MOVER.BAT in the EML folder. Then I ran it. It succeeded in moving less than half of the files, which meant that the spreadsheet had not yet captured hundreds of EML file names correctly. I dir a DIR /b > dirlist.txt in the EMLs folder to capture the names of the ones that had failed. I brought that list into the Excel spreadsheet and matched them up with my attempts. This matching process was sufficiently time-consuming that I found myself grateful for the ones that I had managed to identify in a more automated fashion. The time investment was acceptable. As had been the case for me with spreadsheets going back almost 30 years, I figured that, once I identified the rules and became more familiar with this particular process, I would be able to use it again in similar tasks.
To match up the real filenames with the versions in the spreadsheet, I pasted the contents of dirlist.txt into a separate worksheet in Excel. From both, I compared the date and time data, using VLOOKUP on shortened versions of the relevant colums (=LEFT(Z1,13)). This revealed several things. First, there was an error in how I had converted the date and time data, so I would have to fix that and re-run it to move more of the items from the EML folder into the Test folder. Since I planned on doing this task again, I also decided to automate some of the find-and-replace operations described above. This required using FIND and MID to divide the text string into parts appearing before and after the character I wanted to replace (e.g., colons) and then joining them together without the middle part. I didn't do this for all possible combinations; I was basically interested in eliminating the first and/or most frequent occurrences of the forbidden characters that did seem to appear.
Starting Over: Revise the Filenames, Not the List
After hours of effort and a couple of retries, the approach described above was still identifying (i.e., successfully moving) only about 80% of the EMLs I had exported from Thunderbird. Depending on the total number of emails involved, that could mean hundreds or even thousands of emails that would have to be manually renamed in order to insure that their filenames contained all of the desired data.
I decided that the better approach mgiht be to try to rename the files, and keep renaming them if necessary, until they conformed to certain basic rules in the file list exported into Index.csv. There had already been some of that in the steps described above; the change now was to make that the primary effort.
The first step was to take a listing of the EMLs. This was easy enough: DIR /b > dirlist.txt. Then I copied the contents of that text file into Excel and changed components of the filename to be the way I wanted. The names of EMLs exported from Thunderbird did not have "To" fields, but I was able to match up most of the names automatically with what I had already prepared, thus borrowing To fields from the work described above. (This is a cursory description. At this writing, I had run out of time for this project, and was focused on getting it done. But the basic techniques were as described above.)
Some filenames did not match up easily to support an automated renaming of the EMLs.. I renamed the rest, using a MOVE command to put them into a separate folder. I copied those that did not rename into a separate folder too. These I renamed using the Bulk Renamer (above), so as to have .txt extensions. I did that so that I could view them in IrfanView, which enabled me to flip back and forth among them quickly, so as to identify the proper "To" information.
At this point, I started
a new post to summarize more clearly the steps taken here.